We have already discussed few articles on Ionic. Latest Ionic 3 came up with lazy loading concepts. Changing Ionic apps to use lazy loading significantly boost up the app performance. This actually improves the app speed, instead of loading everything in root application module file. This allows doing the work in sync with when your users want it to happen. This article explains to you how to modify the existing default Ionic app and apply lazy load concepts like working with providers, shared/child components. It process by loading chunks of code such as child components when it’s requested not when the app is loaded. Use this feature and enrich your application. Watch the video, you understand it better.
It is very simple to trigger any camera device and show the resulting output. This has been discussed in my article to take multiple photos with delete action using Ionic and AngularJS. Here is a problem. You can only see the image temporarily, since it has not been stored in any storage. Today’s article will explain to you how to store the captured image in a database, so that you can use it later. I’ll be using RESTful API to achieve this. Look into the demo below and also the code to see how to connect with RESTful API to store any captured image into a database.
MailXEngine is a simple tool for verifying an email address. It ensures you to send email to real users, thereby reduce your bounce rate & reputation, improve email deliverability and save money with MailXEngine. Email is the first line of communication for any digital marketing and online marketers. More the number of invalid emails you have on the email list, more the number of spam complaints, decreased email deliverability and you should even face a higher bounce rate every time. MailxEngine is all here for this as a trusted solution. It increases email deliverability by reducing spam complaints and controlling bounce rate.
We have seen series of posts on developing a mobile application using Ionic and AngularJS. One of my previous articles which deal with insertion and deletion of posts using RESTful API. Similarly, today’s post makes use of RESTful API. These days, a single page web applications are most commonly used ones, because of which there is a need to show loads of data on the same page as we keep on scrolling. This infinite scrolling avoids pagination system.
There are a number of advantages to implementing social login in your web applications. First of all, it best secures the user credentials, the user can use a single login for accessing multiple sites, this can automatically access the user details for further use, and many such. This article is about how to implement the social login with Facebook and Google using ReactJS and RESTful API. This social login helps to store social data of the logged in user into the database. So that it provides you valid user data like email, name, and others. This is a continuation of ReactJS Welcome Page with Routing Tutorial. Let’s see how this works, follow the live demo and code below.
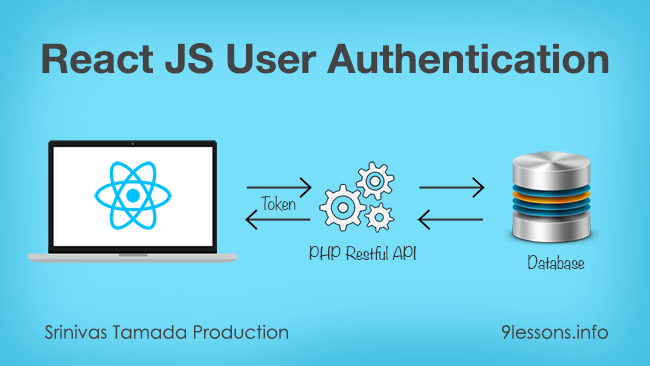
Here is the continued article on my previous post for creating a welcome with login and logout using ReactJS. Today’s post explains how to implement login authentication system for your React JS applications. It will show you how to log in with a user and store the user session, so it deals with token-based authentication. Since we are using token-based authentication, it protects if any unauthorized request is made and notices for a new login if required. This makes your application’s authentication to be more secure compared with any other authentication system. Every user details will be stored in an external database and a PHP based API is used in the backend for handling this authentication. Hope you’ll find it more easily using this as your authentication system in your ReactJS projects. Let’s look into the live demo and follow the below code.
Days back, I have posted an article on how to create a welcome page with proper login and logout using Ionic 3 and Angular 4. Today’s article is to create the same welcome page with ReactJS and ES 6. The article is about how to login/signup to get inside the application home page, you can navigate to different pages and finally you end up with a logout action. Lets see how to set a starting page with navigations using ReactJS and ES 6.
Video Tutorial: ReactJS Welcome Page with Routing Tutorial
It's October and Halloween is around the corner! I'm sure many of you have scary costumes to put together. When you're not spending time planning your costume masterpiece, check out some of the new features available in Firebase Test Lab for Android:
Robo test improvements
Test Lab's automated Robo testleveled up recently! Robo now crawls your app with about double the previous coverage. That means it will reach more screens and take more actions, which boosts its ability to find crashes throughout your app. In fact, the rate of finding crashes has gone up by about 62%. Robo is very motivated to find those scary bugs before they frighten your users away! If you haven't run a Robo test against your app, just upload your APK to Test Lab in the Firebase console at no cost. You also get a Robo test with your pre-launch report in the Play Console. For the crafty among you, you could possibly make your own Robo.
Faster test results
If you run a lot of tests with the gcloud command line, and primarily want to know if your tests simply pass or fail, you can speed up your tests by opting out of some of the extra information that Test Lab collects for you. Passing the --no-record-video flag will opt out of the collection of the video of your app, and --no-performance-metrics will opt out of performance data collected for game loop tests. So use these options to give your tests a good cardio workout for sustained high speed, which is imperative for escaping zombies.
Support for Android Test Orchestrator
The Android Testing Support Library recently published some enhancements to the tooling used to test Android apps. With these updates, you can now make use of Android Test Orchestrator, which helps you isolate your Android test cases and therefore promote more consistent test results. Test Lab now supports this handy utility, so consider making use of it in your test suites today. Here's a gratuitous link to an orchestra in costume.
If you want to chat with the Test Lab team and others in the community who love testing their apps, why don't you join the Firebase Slack and find us in the #test-lab channel? There's no tricks there, only treats.
Hey, did you hear the big news? We just announced the beta release of Cloud Firestore -- the new database that lets you easily store and sync app data to the cloud, even in realtime!
Now if you're experiencing some deja vu, you're not alone. We realize this sounds awfully similar to another product you might already be using -- the Firebase Realtime Database. So if you're experiencing some deja vu, you're not alone.
So why did we build another database? And when would you choose one over another? Well, let's talk about what's new and different with Cloud Firestore, and why you might want to use it for your next app.
What's different with Cloud Firestore?
While our documentation covers all of the differences between the Realtime Database and Cloud Firestore in much more detail, let's look at the main differences between the two products. And we'll start with...
Better querying and more structured data
While the Firebase Realtime Database is basically a giant JSON tree where anything goes and lawlessness rules the land1, Cloud Firestore is more structured. Cloud Firestore is a document-model database, which means that all of your data is stored in objects called documents that consist of key-value pairs -- and these values can contain any number of things, from strings to floats to binary data to JSON-y looking objects the team likes to call maps. These documents, in turn, are grouped into collections.
Your Cloud Firestore database will probably consist of a few collections that contain documents that point to subcollections. These subcollections will contain documents that point to other subcollections, and so on.
This new structure gives you several important advantages in being able to query your data.
For starters, all queries are shallow, meaning that you can simply fetch a document without having to fetch all of the data contained in any of the linked subcollections. This means you can store your data hierarchically in a way that makes sense logically without worrying about downloading tons of unnecessary data.
In this example, the document at the top can be fetched without grabbing any of the documents in the subcollections below
Second, Cloud Firestore has more powerful querying capabilities than the Realtime Database. In the Realtime Database, trying to create a query across multiple fields was a lot of work and usually involved denormalizing your data.
For example, imagine you had a list of cities, and you wanted to find a list of all cities in California with a population greater than 500k.
Cities, stored in the Realtime Database
In the Realtime Database, you'd need to conduct this search by creating an explicit "states plus population" field and then running a query sorted on that field.
Creating a combined state_and_population field, just for queries
With Cloud Firestore, this work is no longer necessary. In some cases, Cloud Firestore can automatically search across multiple fields. In other cases, like our cities example, Cloud Firestore will guide you towards automatically building an index required to make these kinds of queries possible…
...and then you can simply search across multiple fields.
Cloud Firestore will automatically maintain this index for you throughout the lifetime of your app. No combo fields required!
Designed to Scale
While the Realtime Database does scale to meet the needs of most apps, things can start to get difficult when your app becomes really popular, or your dataset gets truly massive.
Cloud Firestore, on the other hand, is built on top of the same Google Cloud infrastructure that powers some pretty popular apps. So it will be able to scale much more easily and to a much greater capacity than the Realtime Database can.
And with the new querying structure, all Cloud Firestore queries scale to the size of your result set -- not the size of your data. This means that a search for the top 10 restaurants in Chicago for a restaurant review app will take the same amount of time whether your database has 300 restaurants, 300 thousand or 30 million. As one engineer here likes to put it, "It's basically impossible to create a slow query in Cloud Firestore."
At the start of our beta period, Cloud Firestore will already allow scaling to levels somewhat greater than that of the Realtime Database, although we are putting a few restrictions around things as we monitor how the database performs in more real-world situations. But look for Cloud Firestore to be able to expand automatically to ludicrous levels2 as we get out of the beta period and move closer to a general availability release.
Easier manual fetching of data
While some developers appreciated the real-time nature of the Realtime Database for building features like chat or enabling magical collaborative experiences, we found that many of our developers simply wanted to use the Realtime Database as a traditional, "Just fetch data when I ask for it" kind of service.
Although the Realtime Database does support this with .once calls, they can sometimes feel a bit unnatural to use and often play second-fiddle to the streaming methods within the SDKs. With Cloud Firestore, making simple one-time fetch queries is much more natural and is built as a primary use case within the Firestore API.
Of course, you can still add support for listeners, so that your clients have the ability to receive updates whenever you data changes in the database. But now you have the flexibility to retrieve your data however you'd like.
Multi-Region support for better reliability
Cloud Firestore is a multi-region database. This means that your data is automatically copied to multiple geographically separate regions at once. So if some unforeseen disaster were to render a data center -- or even an entire region -- offline, you can rest assured that your data is safe.
And for you database aficionados out there, we should point out that our multi-region database offers strong consistency (just like Cloud Spanner!), which means that you get the benefits of multi-region support, while also knowing that you'll be getting the latest version of your data whenever you perform a read.
Different pricing model
The two databases have fairly different pricing models: The Realtime Database primarily determines cost based on the amount of data that's downloaded, as well as the amount of data you have stored on the database.
While Cloud Firestore does charge for these things as well, they are significantly lower than what you would see in the Realtime Database3. Instead, Cloud Firestore's pricing is primarily driven by the number of reads or writes that you perform.
What this means is that if you have a more traditional mobile app where your client is occasionally requesting larger chunks of data from your database -- think something like a news app, a dating app, or a turn-based multiplayer game, for instance -- you will find that Cloud Firestore's pricing model might be more favorable than if you ran the same app on the Realtime Database.
On the other hand, if you have an app that's making very large numbers of reads and writes per second per client (for instance, a group whiteboarding app, where you might be broadcasting everybody's drawing updates to everybody else several times a second), Cloud Firestore will probably be more expensive.4 At least for that portion of your app -- you can always use both databases together, and that's fine, too.
Of course these are just rough guidelines, make sure you check out the Pricing section of our documentation for all the details on Cloud Firestore pricing.
Why you still might want to use the Realtime Database
With this list of changes, you might come away with the impression that Cloud Firestore is simply better than the Realtime Database. And while Cloud Firestore does have a fair number of improvements over the Realtime Database, there are still situations where you might want to consider using the Realtime Database for some of your data. Specifically…
The Realtime Database will probably have slightly better latency. Usually not by much -- maybe a couple hundred milliseconds from the database to the client -- but if you're looking for a database with reliably low-latency updates to power an app that feels instant, you might prefer the Realtime Database.
The Realtime Database has native support for presence -- that is, being able to tell when a user has come online or gone offline. While we do have a solution for Cloud Firestore, it's not quite as elegant.
As we noted above, Cloud Firestore's pricing model means that applications that perform very large numbers of small reads and writes per second per client could be significantly more expensive than a similarly performing app in the Realtime Database.
Cloud Firestore is still a beta product. The Realtime Database has been available for four years and has been battle-tested by hundreds of thousands of production-level apps. Cloud Firestore has seen limited production usage over the last few months by several dozen apps. And while some of these apps -- like HomeAwayand Hawkin Dynamics -- are already out in the real world and performing quite nicely, there will likely be issues or edge cases with Cloud Firestore that we simply haven't discovered yet.
The tl;dr: Just tell me what to use!
In general, we recommend that most new applications start with Cloud Firestore, unless you think that your app has unique needs, like those we outlined above, that make it more suitable for the Realtime Database.
On the other hand, if you have an existing database that's already running just fine on the Realtime Database, go ahead and keep it there! If you find you're running up against issues where Cloud Firestore could really help you out, then you could consider switching, or moving part of your data to Cloud Firestore and using both databases together. But don't switch just for the sake of switching.
And if you're looking for a magic, "Please convert my database from the Realtime Database to Cloud Firestore" button, there isn't one5! And, frankly, we don't know if there ever will be. Given how different the database, querying, and pricing structures are between the two, blindly converting a database that's been optimized for the Realtime Database over to Cloud Firestore wouldn't necessarily be a great experience. We want you to be more thoughtful about making this kind of change.
There's a lot we think you'll be able to do with Cloud Firestore and we're excited to see what kinds of apps you're able to build with it. As always, if you have questions, you can hit us up on any of our support channels, or post questions on Stack Overflow with the google-cloud-firestoreand firebase tags. Good luck, and have fun!
Today we're excited to launch Cloud Firestore, a fully-managed NoSQL document database for mobile and web app development. It's designed to easily store and sync app data at global scale, and it's now available in beta.
Key features of Cloud Firestore include:
Documents and collections with powerful querying
iOS, Android, and Web SDKs with offline data access
Real-time data synchronization
Automatic, multi-region data replication with strong consistency
Node, Python, Go, and Java server SDKs
And of course, we've aimed for the simplicity and ease-of-use that is always top priority for Firebase, while still making sure that Cloud Firestore can scale to power even the largest apps.
Optimized for app development
Managing app data is still hard; you have to scale servers, handle intermittent connectivity, and deliver data with low latency.
We've optimized Cloud Firestore for app development, so you can focus on delivering value to your users and shipping better apps, faster. Cloud Firestore:
Synchronizes data between devices in real-time. Our Android, iOS, and Javascript SDKs sync your app data almost instantly. This makes it incredibly easy to build reactive apps, automatically sync data across devices, and build powerful collaborative features -- and if you don't need real-time sync, one-time reads are a first-class feature.
Uses collections and documents to structure and query data. This data model is familiar and intuitive for many developers. It also allows for expressive queries. Queries scale with the size of your result set, not the size of your data set, so you'll get the same performance fetching 1 result from a set of 100, or 100,000,000.
Enables offline data access via a powerful, on-device database. This local database means your app will function smoothly, even when your users lose connectivity. This offline mode is available on Web, iOS and Android.
Enables serverless development. Cloud Firestore's client-side SDKs take care of the complex authentication and networking code you'd normally need to write yourself. Then, on the backend, we provide a powerful set of security rules so you can control access to your data. Security rules let you control which users can access which documents, and let you apply complex validation logic to your data as well. Combined, these features allow your mobile app to connect directly to your database.
Integrates with the rest of the Firebase platform. You can easily configure Cloud Functions to run custom code whenever data is written, and our SDKs automatically integrate with Firebase Authentication, to help you get started quickly.
Putting the 'Cloud' in Cloud Firestore
As you may have guessed from the name, Cloud Firestore was built in close collaboration with the Google Cloud Platform team.
This means it's a fully managed product, built from the ground up to automatically scale. Cloud Firestore is a multi-region replicated database that ensures once data is committed, it's durable even in the face of unexpected disasters. Not only that, but despite being a distributed database, it's also strongly consistent, removing tricky edge cases to make building apps easier regardless of scale.
It also means that delivering a great server-side experience for backend developers is a top priority. We're launching SDKs for Java, Go, Python, and Node.js today, with more languages coming in the future.
Another database?
Over the last 3 years Firebase has grown to become Google's app development platform; it now has 16 products to build and grow your app. If you've used Firebase before, you know we already offer a database, the Firebase Realtime Database, which helps with some of the challenges listed above.
The Firebase Realtime Database, with its client SDKs and real-time capabilities, is all about making app development faster and easier. Since its launch, it has been adopted by hundred of thousands of developers, and as its adoption grew, so did usage patterns. Developers began using the Realtime Database for more complex data and to build bigger apps, pushing the limits of the JSON data model and the performance of the database at scale. Cloud Firestore is inspired by what developers love most about the Firebase Realtime Database while also addressing its key limitations like data structuring, querying, and scaling.
So, if you're a Firebase Realtime Database user today, we think you'll love Cloud Firestore. However, this does not mean that Cloud Firestore is a drop-in replacement for the Firebase Realtime Database. For some use cases, it may make sense to use the Realtime Database to optimize for cost and latency, and it's also easy to use both databases together. You can read a more in-depth comparison between the two databases here.
We're continuing development on both databases and they'll both be available in our console and documentation.
Get started!
Cloud Firestore enters public beta starting today. If you're comfortable using a beta product you should give it a spin on your next project! Here are some of the companies and startups who are already building with Cloud Firestore:
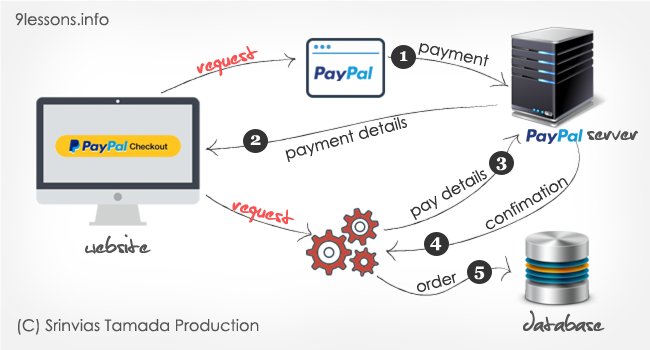
Most of the people prefer to shop online which made eCommerce to grow rapidly. But, what makes an excellent eCommerce site for the customers? The answer is - an excellent checkout process. There are several different payment options available in the market today. Out of all, Paypal is the most popular and convenient way to get paid. Making it as easy as possible for your customers to pay is essential for increasing conversions and sales. This is why your checkout page is critical. I have already discussed 2 checkout options in my previous articles BrainTree PayPal using PHP and Payment System which were in most trend till day. Now, a new checkout option has been introduced by Paypal which is Paypal Express Checkout option.
Developer Advocate If you've been working with Cloud Functions for Firebase, you've probably wondered how you could speed up the development of your functions. This is possible for HTTPS type functions using the firebase serve in the Firebase CLI, but this wasn't an option for other types of functions. Now, local testing of all of your functions is easy with the Firebase CLI. If you want to try out your code before you deploy it to Cloud Functions, you can do that with the Cloud Functions shell in the Firebase CLI starting at version 3.11.0 or later.
Here's how it works, in a nutshell. We'll use a Realtime Database trigger as an example.
Imagine you have an existing project with a single function in it called makeUppercase. It doesn't have to be deployed yet, just defined in your index.js:
This onCreate database trigger runs when a new message is pushed under /messages with a child called original, and writes back to that message a new child called uppercased with the original value capitalized.
Now, if you can kick off the emulator shell from your command line using the Firebase CLI:
$ cd your_project_dir $ firebase experimental:functions:shell
Then, you'll see something like this:
i functions: Preparing to emulate functions. ✔ functions: makeUppercase firebase>
That firebase prompt is waiting there for you to issue some commands to invoke your makeUppercase function. The documentation for testing database triggers says that you can use the following syntax to invoke the function with incoming data to describe the event:
makeUppercase('foo')
This emulates the trigger of an event that would be generated when a new message object is pushed under /messages that has a child named original with the string value "foo". When you run this command in the shell, it will generate some output at the console like this:
info: User function triggered, starting execution info: Uppercasing pushId1 foo info: Execution took 892 ms, user function completed successfully
Notice that the console log in the function is printed, and it shows that the database path wildcard pushId was automatically assigned the value pushId1 for you. Very convenient! But you can still specify the wildcard values yourself, if you prefer:
After emulating this function, if you look inside the database, you should also see the results of the function on display, with /messages/{pushId}/uppercased set to the uppercased string string value "FOO".
You can simulate any database event this way (onCreate, onDelete, onUpdate, onWrite). Be sure to read the docs to learn how to invoke them each correctly.
The Cloud Functions shell is currently an experimental offering, and as such, you may experience some rough edges. If you encounter a problem, please let us know by filing a bug report. You can also talk to other Cloud Functions users on the Firebase Slack in the #functions channel.
Some tips for using the shell
Typing the function invocation each time can be kind of a pain, so be sure to take advantage of the fact that you can navigate and repurpose your invocation history much like you would your shell's command line using the arrow keys.
Also note that the shell is actually a full node REPL that you can use to execute arbitrary JavaScript code and use special REPL commands and keys. This can be useful for scripting some of your test code.
Since you can execute arbitrary code, you can also dynamically load and execute code from other files using the require() function that you're probably already familiar with.
And lastly, if you're like me, and you prefer to use a programmer's editor such as VS Code to write your all JavaScript, you can easily emulate functions by sending code you want to run to the Firebase CLI. This command will run test code from a file redirected through standard input:
A newcomer to the ridesharing space, Sprynt is taking adifferent approach to building its service. They have a 100% electric fleet and rides are 100% free, paid for by local and corporate sponsorships. So when they first contacted our agency Savvy Apps, we were excited about the opportunity to work with them. We knew on the technology side, though, that Sprynt would pose some unique challenges. After considering a few options, we decided to use Firebase to tackle these challenges and create the best experience for riders, drivers, and the Sprynt management team.
Prioritizing real-time communication and queue management
One of the most important components of a ridesharing app is keeping everything synced in real-time. Sprynt needed fast and reliable synchronized rider and driver apps, GPS tracking, and ride-request queue management. That's why one of the first features that attracted us to Firebase for this app was the Realtime Database.
We leveraged Firebase's synchronization solution for its speed, as well as the Realtime Database listeners for keeping the system fast and lightweight. In our experience, Firebase excels when dealing with simple data schemas that need real-time communication between clients and server.
Extending to a complete solution
Besides the core product requirement of real-time communication, Sprynt needed a platform that could support a fully-featured app. For example: authentication for registering and logging in, notifications to help with rider and driver communication, and an easy-to-use dashboard to help the Sprynt team understand and manage their system.
Firebase has all of these components, which made it a leading candidate and our eventual choice. It provides the ability to quickly set up and scale a backend with authentication, push notifications, custom cloud functions, file storage, and analytics. The dashboards and admin tools also allow us to stay focused on building what matters most: a compelling user experience. Simply put, Firebase let Savvy begin a product like Sprynt quickly without compromise.
For authentication, we turned to Firebase Auth because we wanted to take advantage of the new phone authentication added this year at Google I/O. We were able to quickly build an authentication mechanism that allowed for users to sign up via phone numbers. This feature was an important one for Sprynt, since it streamlined the onboarding process. That's especially important when someone might want to get started with Sprynt in a hurry.
When it came to building in notifications, we used Firebase Cloud Messaging. FCM allowed us to send notifications programmatically, such as when a driver is on the way to a rider. Beyond that, FCM gives Sprynt admins the ability to send out quick one-off messages to their user base through the notifications dashboard. We feel that this functionality will prove invaluable for handling services outages, highlighting new specials from advertisers, or other comparable communication regarding the Sprynt service.
Ensuring Sprynt's longevity
Sprynt launched to great success. In the first month of service, they delivered around 5,000 passengers in their pilot service area. The app maintains a 5-star rating and their advertisers are very happy with their results so far.
Sprynt is already pushing hard to keep up with demand from riders and advertisers, as well as the influx of new driver applications. They also have already begun building a steady, repeat ridership base. Google Analytics for Firebase has proven helpful in tracking this kind of usage, as well as version update adoption rates, user device types, and custom events.
We built Sprynt using Firebase for long-term sustainability without constant developer involvement. By leveraging the Firebase console, we made it as easy as possible for Sprynt's team to manage their business, with as little development support as needed. Cloud Storage for Firebase plus Cloud Functions for Firebase allow Sprynt to upload and process updated or new service areas without directly editing the database. These features will become even more important as Sprynt continues to grow in popularity and open new service areas.
A smooth ride
While Firebase Realtime Database has some weaknesses in its query support — particularly around complex queries that include filtering and sorting collections — overall, we've been happy with the platform and its progress.
We've used Firebase since it launched years ago, but we continue to appreciate when the observeSingleEventOfType function on one device responds to an event triggered by another. Watching it happen for the first time between the Sprynt Rider app and Sprynt Driver app still provides that "aha" moment, even today.
Firebase continues to enhance our ability to build and scale new businesses as quickly as possible.
Originally posted on the Fabric Blog by Jason St. Pierre, Product Manager
For many years, developers and app teams have relied on Crashlytics to improve their app stability. By now, you're probably familiar with the main parts of the Crashlytics UI; perhaps you even glance at crash-free users, crash-free sessions, and the issues list multiple times a day (you wouldn't be the only one!).
In this post, we want to share 7 pro-tips that will help you get even more value out of Crashlytics, which is now part of the new Fabric dashboard, so you can track, prioritize, and solve issues faster.
1. Speed up your troubleshooting by checking out crash insights
In July, we officially released crash insights out of beta. Crash insights helps you understand your crashes better by giving you more context and clarity on why those crashes occurred. When you see a green lightning bolt appear next to an issue in your issues list, click on it to see potential root causes and troubleshooting resources.
2. Mark resolved issues as "closed" to track regressions
Debugging and troubleshooting crashes is time-consuming, hard work. As developers ourselves, we understand the urge to sign-off and return to more exciting tasks (like building new app features) as soon you resolve a pesky issue - but don't forget to mark this issue as "closed" in Crashlytics! When you formally close out an issue, you get enhanced visibility into that issue's lifecycle through regression detection. Regression detection alerts you when a previously closed issue reoccurs in a new app version, which is a signal that something else may be awry and you should pay close attention to it.
3. Close and lock issues you want to ignore and declutter your issue list
As a general rule of thumb, you should close issues so you can monitor regression. However, you can also close and lock issues that you don't want to be notified about because you're unlikely to fix or prioritize them. These could be low-impact, obscure bugs or issues that are beyond your control because the problem isn't in your code. To keep these issues out of view and declutter your Crashlytics charts, you can close and lock them. By taking advantage of this "ignore functionality", you can fine tune your stability page so only critical information that needs action bubbles up to the top.
4. Use wildcard builds as a shortcut for adding build versions manually
Sometimes, you may have multiple builds of the same version. These build versions start with the same number, but the tail end contains a unique identifier (such as 9.12 (123), 9.12 (124), 9.12 (125), etc). If you want to see crashes for all of these versions, don't manually type them into the search bar. Instead, use a wildcard to group similar versions together much faster. You can do this by simply adding a star (aka. an asterisk) at the end of your version prefix (i.e. 9.12*). For example, if you use APK Splits on Android, a wildcard build will quickly show you crashes for the combined set of builds.
5. Pin your most important builds to keep them front and center
As a developer, you probably deploy a handful of builds each day. As a development team, that number can shoot up to tens or hundreds of builds. The speed and agility with which mobile teams ship is impressive and awesome. But you know what's not awesome? Wasting time having to comb through your numerous builds to find the one (or two, or three, etc.) that matter the most. That's why Crashlytics allows you to "pin" key builds so that they appear at the top of your builds list. Pinned builds allow you to find your most important builds faster and keep them front and center, for as long as you need. Plus, this feature makes it easier to collaborate with your teammates on fixing crashes because pinned builds will automatically appear at the top of their builds list too.
6. Pay attention to velocity alerts to stay informed about critical stability issues
Stability issues can pop up anytime - even when you're away from your workstation. Crashlytics intelligently monitors your builds to check if one issue has caused a statistically significant number of crashes. If so, we'll let you know if you need to ship a hot fix of your app via a velocity alert. Velocity alerts are proactive alerts that appear right in your crash reporting dashboard when an issue suddenly increases in severity or impact. We'll send you an email too, but you should also install the Fabric mobile app, which will send you a push notification so you can stay in the loop even on the go. Keep an eye out for velocity alerts and you'll never miss a critical crash, no matter where you are!
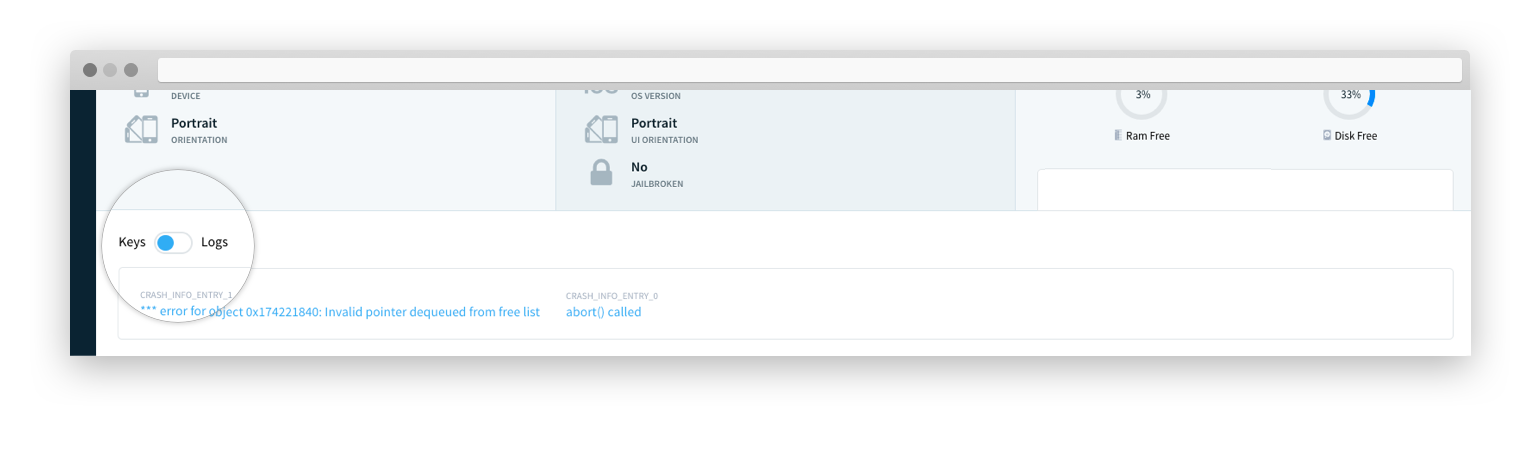
7. Use logs, keys, and non-fatals in the right scenarios
The Crashlytics SDK lets you instrument logs, keys, non-fatals, and custom events, which provide additional information and context on why a crash occurred and what happened leading up to it. However, logs, keys, non-fatals, and custom events are designed to track different things so let's review the right way to use them.
Logs: You should instrument logs to gather important information about user activity before a crash. This could be user behavior (ex. user went to download screen, clicked on download button) to details about the user's action (ex. image downloaded, image downloaded from). Basically, logs are breadcrumbs that show you what happened prior to a crash. When a crash occurs, we take the contents of the log and attach it to the crash to help you debug faster. Here are instructions for instrumenting logs for iOS, Android, and Unityapps.
Keys: Keys are key value pairs, which provide a snapshot of information at one point in time. Unlike logs, which record a timeline of activity, keys record the last known value and change over time. Since keys are overwritten, you should use keys for something that you would only want the last known value for. For example, use keys to track the last level a user completed, the last step a user completed in a wizard, what image the user looked at last, and what the last custom settings configuration was. Keys are also helpful in providing a summary or "roll-up" of information. For instance, if your log shows "login, retry, retry, retry" your key would show "retry count: 3." To set up keys, follow these instructions for iOS, Android, and Unityapps.
Non-fatals: While Crashlytics captures crashes automatically, you can also record non-fatal events. Non-fatal events mean that your app is experiencing an error, but not actually crashing.
For example, a good scenario to log a non-fatal is if your app has deep links, but fails to navigate to them. A broken link isn't something that will necessarily crash your app, but it's something you'd want to track so you can fix the link. A bad scenario to log a non-fatal is if an image fails to load in your app due to a network failure because this isn't actionable or specific.
You should set up non-fatal events for something you want the stack trace for so you can triage and troubleshoot the issue.
If you simply want to count the number of times something happens (and don't need the stack trace), we'd recommend checking out custom events.
These 7 tips will help you get the most out of Crashlytics. If you have other pro-tips that have helped you improve your app stability with Crashlytics, tweet them at us! We can't wait to learn more about how you use Crashlytics.
We've provided a number of different ways for you to get started building your app with the Firebase platform -- everything from quickstarts for many of our individual products, to codelabs, to some Getting Started screencasts on our YouTube channel.
But what happens after you've gotten started with a feature, and are looking to build something more substantial? How do you learn how to avoid race conditions while writing to the Firebase Database? Or lazily create an infinite feed? Do you wish there were an open-sourced Firebase playbook app that you could use to see real-life use cases in motion? Or an app that demonstrates the use of multiple Firebase products together, so you can follow the same practices in your own app?
For all you developers who want to see an app built for a real life scenario, we've created an open sourced narrative app called FriendlyPix. FriendlyPix uses some of the most popular Firebase SDKs, such as Analytics, Cloud Messaging, Cloud Functions, Authentication (with FirebaseUI), Realtime Database, Storage, Remote Config, Invites, and AdMob.
Best Practices
FriendlyPix highlights some of the best practices when using Firebase, such as:
Using FirebaseUI for Auth
Creating indexes in the Realtime Database for fast search
Fanning out simultaneous writes to avoid race conditions
Building a data hierarchy of flat, denormalized data for fast access
Running ordered, filtered queries for partial data access
Creating lazily updated feeds
Using the proper file and folder structure when uploading images to Firebase Storage in conjunctions with Cloud Functions
We look forward to seeing you use these best practices in your app, or use FriendlyPix as a starting point for your app.
The web version is already hosted at https://friendly-pix.com for you to try out, and we are planning to release FriendlyPix on other platforms for you try as well.
We'll be updating the app and adding further SDKs in the coming weeks, so keep an eye on this blog or watch our Github repos to stay updated.
Questions / Issues / Contribute
You can ask FriendlyPix related questions on StackOverflow with the firebase and friendlypix tags. Issue trackers are hosted on Github in their respective platforms repos: Web, iOS, and Android. We'd love for you to contribute to the project, although before doing so please read our Contributor guide.
Perhaps you're already familiar with Firebase Dynamic Links -- smart URLs that take the user to any location within your iOS or Android app, even if your user needs to install the app first. Over the last couple of months, the team has made some nice improvements to Dynamic Links, particularly on the iOS side of things, that will make it easier for you to use them in your apps. Let's take a look at what's new!
Better App Preview page
A while back, the Dynamic Links team added an App Preview page for situations where a user clicked on a link and didn't have the app installed on iOS. We added this because some apps -- particularly popular social ones -- tended to ignore the JavaScript redirect that took users to the App Store. So these App Preview pages provided a way to ensure that users still ended up at the App Store, like you intended. It was also a nicer experience for many users, because they were better prepared to see the App Store come up.
That said, our initial page was a little… spartan. Since introducing this page, we've made a few improvements to dress it up with graphics and assets taken either from your app store's listing in the app store, or from preview assets that you can specify directly. We've found this has lead to a significant bump in the number of users who continue to click through to the app store. And it looks better, too.
App Preview pages: Before, the newer default version, and one with custom assets
Of course, if you're still not excited about the idea of having an App Preview page, you're always welcome to remove it. You can do this by adding efr=1to the dynamic link URL you're generating, checking the "Skip the app preview page" checkbox in the Firebase Console, or using the forcedRedirectEnabled parameter in the iOSand Androidbuilder APIs.
Better error messages -- now with links!
In many cases now, when you encounter error messages in your Dynamic Links implementation, we'll provide you with direct links to our documentation that describe in more detail exactly what these errors mean, and how to fix 'em. Wow! Who knew links could be used as a way to redirect users to more content that's of interest to them? Oh, wait. We did. That's our entire product.
Self-diagnostic tools on iOS
While we're on the subject of making it easier for you to implement Dynamic Links, we've also included self-diagnostic tools with the Dynamic Links library on iOS. By calling DynamicLinks.performDiagnostics(completion: nil)anywhere within your code, the Dynamic Links library can analyze your project and let you know if it detects any common errors with your setup. It also gives you some helpful information that you should send to our troubleshooting team, if you ever need to reach out to them.
More detailed analytics
In the past, when you generated a short Dynamic Link via the console, we were able to tell you how many times per day that link was clicked. While that was nice and all, we've recently boosted our analytics reports to include some more detailed information. Now we can tell you how many times per day a user re-opened your app because they clicked on a Dynamic Link, as well as how many times per day your short Dynamic Link resulted in a user opening up your app for the first time. This holds true both for the analytics you get from the Firebase Console, and also for the analytics you can retrieve using our REST API.
And, as always, if you want to add in utm parameters to your Dynamic Links, Google Analytics for Firebase can make sure it attributes any important conversion events to the Dynamic Link that brought the user to your app in the first place.
Give 'em a try!
All of these changes are on top of a bunch of other improvements we've made to Firebase Dynamic links over the past few months, including:
Adding a REST API for retrieving analytics information on your short Dynamic Links, in case you want analytics information but just don't feel like visiting the Firebase Console
A link debugging page that shows you, through a pretty fantastic flow chart, exactly what will happen in every situation when a user clicks on a dynamic link
So if you haven't tried Firebase Dynamic Links lately, this would be a great time to give 'em a try! You can check out all of our documentation to get started, and you can always reach us through our support channels.
Originally posted by By Nathan Welch, Engineering Director/Co-founder, Smash.gg on the Google Cloud Platform Blog
[Editor's note: Smash.gg is an esports platform used by players and organizers worldwide, running nearly 2,000 events per month with 60,000+ competitors, and recently hosted brackets for EVO 2017, the world's largest fighting game tournament. This is its first post in a multi-part series about migrating to Google Cloud Platform (GCP) -- what got them interested in GCP, why they migrated to it, and a few of the benefits they've seen as a result. Stay tuned for future posts that will cover more technical details about migrating specific services.]
Players in online tournaments running on smash.gg need to be able to interact in real time. Both entrants must confirm that they are present, set up the game, and reach a consensus on the results of the match. They also need a simple chat service to resolve any issues with joining or reporting the match, to talk to one another and to tournament moderators.
We built our initial implementation of online match reporting with an off-the-shelf chat service and UI interactions that weren't truly real-time. When the chat service failed in a live tournament, it became clear that we needed a better solution. We looked into building our own using a websocket-based approach, and a few services like PubNub and Firebase. Ultimately, we decided to launch with Firebase because it's widely used, is backed by Google, and is incredibly well-priced.
Two players checking into, setting up, and reporting an online match using the Firebase Realtime Database for real-time interactions.
We got our start with Firebase in May, 2016. Our first release used the Firebase Realtime Databaseas a kind of real-time cache to keep match data in sync between both entrants. When matches were updated or reported on our backend, we also wrote the updated match data to Firebase. We use React and Flux so we made a wrapper component to listen to Firebase and dispatch updated match data to our Flux stores. Implementing a chat service with Firebase was similarly easy. Using Firechat as inspiration, it took us about a day to build the initial implementation and another day to make it production-ready.
Compared with rolling our own solution, Firebase was an obvious choice given the ease of development and time/financial cost savings. Ultimately, it reduced the load on our servers, simplified our reporting flow, and made the match experience truly real-time. Later that year, we started using Firebase Cloud Messaging (FCM) to send browser push notifications using Cloud Functions triggers as Firebase data changed (e.g., to notify admins of moderator requests). Like the Realtime Database, Cloud Functions was incredibly easy to use and felt magical the first time we used it. Cloud Functions also gave us a window into how well Firebase interacts with Google Cloud Platform (GCP) services like Cloud Pub/Sub and Google BigQuery.
Migrating to GCP
In March of 2017 we attended Google Cloud Next '17 for the Cloud Functions launch. There, we saw that other GCP products had a similar focus on improving the developer experience and lowering development costs. Current products like Pub/Sub, Stackdriver Trace and Logging, and Google Cloud Datastore solved some of our immediate needs. Out of the box, these services gave us things that we were planning to build to supplement products from our existing service provider. And broadly speaking, GCP products seemed to focus on improving core developer workflows to reduce development and maintenance time. After seeing some demos of the products interacting (e.g., Google Container Engineand App Engine with Stackdriver Trace/Logging, Stackdriver with Pub/Sub and BigQuery), we decided to evaluate a full migration.
We started migrating our application in mid May, using the following services: Container Engine, Pub/Sub, Google Cloud SQL, Datastore, BigQuery, and Stackdriver. During the migration, we took the opportunity to re-architect some of our core services and move to Kubernetes. Most of our application was already containerized but had previously been running on a PaaS-like service so Kubernetes was a fairly dramatic shift. While Kubernetes had many benefits (e.g., industry standard, more efficient use of cloud instances, application portability, and immutable infrastructure defined in code), we also lost some top-level application metrics that our previous PaaS service had provided: for instance overall Requests Per Second (RPS), RPS by status, and latency. We were able to easily recreate these graphs from our container logs using log-based metrics and logs export from Stackdriver to BigQuery. You could also do this using other services, but our GCP-only approach was a quick and mostly free way for us to get to parity while experimenting with GCP services.
Request timing and analysis using Stackdriver Trace was another selling point in GCP that we didn't have with our previous service. However, at the time of our migration, the Trace SDK for PHP (our backend services are in PHP, but I promise it's nice PHP!) didn't support asynchronous traces. The Google Cloud SDK for PHP has since added async trace support, but we were able to build async tracing by quickly gluing some GCP services together:
We built a trace reporter to log out traces as JSON.
We then sent the traces to a Pub/Sub topic using Stackdriver log exports.
Finally, we made a Pub/Sub subscriber in Cloud Functions to report the traces using the REST API.
The Google Cloud SDK is certainly a more appropriate solution for tracing in production, but the fact that this combination of services worked well speaks to how easy it is to develop in GCP.
Post-migration results
After running our production environment on GCP for a month, we've saved both time and money. Overall costs are ~10% lower without any Committed Use Discounts, with capacity to spare. Stackdriver logging/monitoring, Container Engine, and Kubernetes have made it easier for our engineers to perform DevOps tasks, leveling up our entire team. And being able to search all our logs in one centralized place allows us to easily cross-reference logs from multiple systems, making it possible to track down root causes of issues much faster. This combined with fully-managed, usage-priced services like Datastore and Firebase means development on GCP is easier and more accessible to all of our engineers. We're really glad we migrated to GCP, and look forward to telling you more about how we did it in future posts. Meanwhile, if you're a developer who loves competitive play and would like to help us build cool things on top of GCP, we'd love to hear from you.We recently closed our Series A from Spark Capital, Accel, and Horizon Ventures, and we're hiring!
A few days back, I read an article about Google Authentication. A bug was mentioned in the article, that Google login status can be easily accessed by calling out some images. After reading the article, I got an idea that why don't we use this bug in a positive approach to validate user authentication. This same idea has been implemented in this post to do email validation. I have used Google email login system (not OAuth) using Angular 4 CLI project. Take a look at the live demo ( Make sure to login into your Google account in another tab to do this validation).
The Firebase Admin SDK for Go is now generally available. This is the fourth programming language to join our growing family of Admin SDKs, which already includes support for Java, Python and Node.js. Firebase Admin SDKs enable application developers to programmatically access Firebase services from trusted environments. They complement the Firebase client SDKs, which enable end users to access Firebase from their web browsers and mobile devices. The initial release of the Firebase Admin SDK for Go comes with some Firebase Authentication features: custom token minting and ID token verification.
Initializing the Admin SDK for Go
Similar to the other Firebase Admin SDKs, the Go Admin SDK can be initialized with a variety of authentication credentials and client options. The following code snippet shows how to initialize the SDK using a service account credential obtained from the Firebase console or the Google Cloud console:
If you are running your code on Google infrastructure, such as Google App Engine or Google Compute Engine, the SDK can auto-discover application default credentials from the environment. In this case you do not have to explicitly specify any credentials when initializing the Go Admin SDK:
The initial release of the Firebase Admin SDK for Go comes with support for minting custom tokens and verifying Firebase ID tokens. The custom token minting allows you to authenticate users using your own user store or authentication mechanism:
The resulting custom token can be sent to a client device, where it can be used to initiate an authentication flow using a Firebase client SDK. On the other hand, the ID token verification facilitates securely identifying the currently signed in user on your server:
To learn more about using the Firebase Admin SDK for Go, see our Admin SDK setup guide.
What's Next?
We plan to further expand the capabilities of the Go Admin SDK by implementing other useful APIs such as user management and Firebase Cloud Messaging. This SDK is also open source. Therefore we welcome you to browse our Github repo and get involved in the development process by reporting issues and sending pull requests. To all Golang gophers out there, happy coding with Firebase!
Every mobile developer needs to take app screenshots in order to have their app listed on the app stores. Like a book cover, screenshots are crucial in depicting the best parts of your app and convincing potential users to download it.
Unfortunately, generating app screenshots is a huge pain because they take a ton of time, especially if your app supports different locales and languages. For example, if you need to take 5 screenshots for your app store listing - but your app supports 20 languages for 6 devices - you'll manually have to take 600 screenshots (5 x 20 x 6)! It makes us shudder to think how many precious hours that would eat up.
fastlane's snapshot tool automates the process of taking screenshots (in the background) so you can focus on building features users love. Today, we're excited to share that snapshot now supports multiple, concurrent simulators for iOS apps in Xcode 9. Taking screenshots just got even faster because you can now generate screenshots for all of your devices at the same time!
Speeding up screenshots (even more!)
Before Xcode 9, only one simulator could be running at a time, which means that you had to run snapshot once for each device you wish to support. While snapshot automated the process of taking screenshots, we wanted to make things even easier.
The launch of Xcode 9 gave us another opportunity to improve snapshot. In Xcode 9, multiple UI tests can run simultaneously, so we added multiple simulator support to snapshot as well. Now, you can take screenshots for all specified devices with a single command, at the same time. This drastically shortens the time it takes to generate your screenshots.
Here's an example:
More exciting updates on the way
fastlane's mission is to save you time by automating the cumbersome tasks of app deployment, even as mobile evolves. That's why we're fully committed to updating the fastlane toolset to take advantage of new releases and features - such as Xcode 9.
And since fastlane is open source, we're so thankful that our community also helps us make fastlane better by building and using plugins. In fact, we now have more user-generated plugins available for you to try than native fastlane actions. We recently reorganized these plugins to make it easier to find the right plugins for your unique needs.
We always strive to anticipate your needs and build our tools to be ready for the future. To start using the new version of snapshot, simply update fastlane and run snapshot as you normally would. If you're taking screenshots manually, check out our guide to start using snapshot (and enjoy the extra free time!). As always, we can't wait to hear what you think!





































 Originally posted by By Nathan Welch, Engineering Director/Co-founder, Smash.gg on the Google Cloud Platform Blog
Originally posted by By Nathan Welch, Engineering Director/Co-founder, Smash.gg on the Google Cloud Platform Blog




{kind=link}